We have a Microsoft Azure IoT Account that serves speech-to-text function
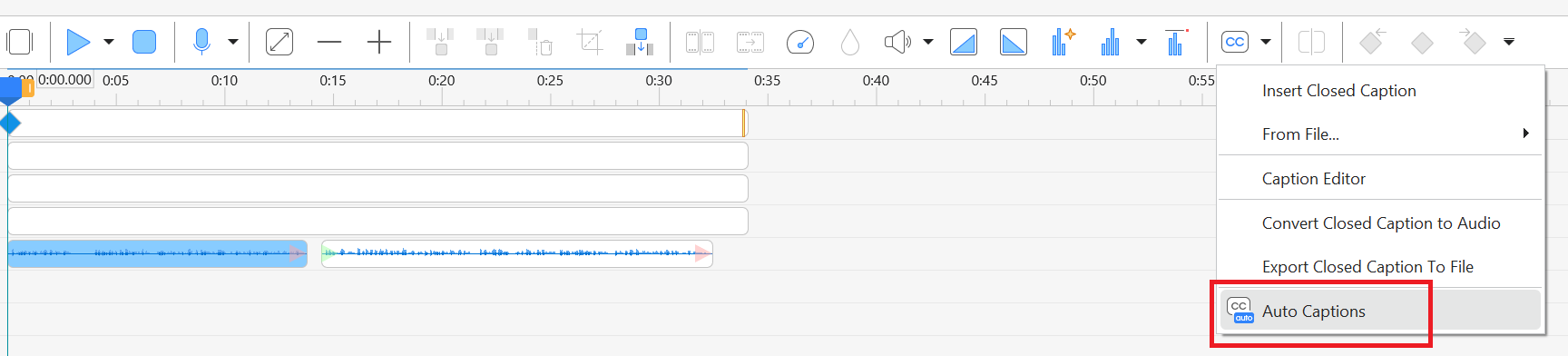
I want to use the ActivePresenter (version 10.0.0) to “Auto Captions” function for turn my speech into caption text. I have recognized in AP that using a custom provider (next to default google) like Microsoft requires an own script.
So I used chaGPT to write me a python script to use the Microsoft speech-to-text API as described here
SPEECH_KEY = “xxxxxxxxxxxxx”SPEECH_REGION = “westeurope”
def get_info():return {“auto-lang”: True,“languages”: [“de-DE”, “en-US”, “en-GB”, “fr-FR”, “es-ES”, “it-IT”,“pt-BR”, “pt-PT”, “nl-NL”, “sv-SE”, “no-NO”, “da-DK”,“fi-FI”, “pl-PL”, “cs-CZ”, “sk-SK”, “ro-RO”, “hu-HU”,“tr-TR”, “ru-RU”, “uk-UA”, “el-GR”, “he-IL”,“ar-SA”, “hi-IN”, “th-TH”, “vi-VN”, “id-ID”, “ms-MY”,“ja-JP”, “ko-KR”, “zh-CN”, “zh-TW”]}
def speech_to_text(audio_path, language_codes, progress_callback=None):import os, json, threadingtry:import azure.cognitiveservices.speech as speechsdkexcept ImportError:raise_error(“Azure Speech SDK for Python missing. Install with: pip install azure-cognitiveservices-speech”)
key, region = _get_azure_credentials()
if not key or not region:
raise_error("Azure credentials missing. Set SPEECH_KEY/SPEECH_REGION or environment variables AZURE_SPEECH_KEY / AZURE_SPEECH_REGION.")
speech_config = speechsdk.SpeechConfig(subscription=key, region=region)
speech_config.output_format = speechsdk.OutputFormat.Detailed
speech_config.request_word_level_timestamps()
audio_config = speechsdk.audio.AudioConfig(filename=audio_path)
if language_codes:
auto_detect = speechsdk.languageconfig.AutoDetectSourceLanguageConfig(languages=language_codes)
else:
auto_detect = speechsdk.languageconfig.AutoDetectSourceLanguageConfig()
recognizer = speechsdk.SpeechRecognizer(
speech_config=speech_config,
audio_config=audio_config,
auto_detect_source_language_config=auto_detect
)
segments = []
done = threading.Event()
def ticks_to_ms(ticks):
return int(round(ticks / 10000.0))
def on_recognized(evt: speechsdk.SessionEventArgs):
result = evt.result
if result.reason != speechsdk.ResultReason.RecognizedSpeech:
return
json_str = result.properties.get(speechsdk.PropertyId.SpeechServiceResponse_JsonResult)
best_text = result.text or ""
words_list = []
seg_start = ticks_to_ms(result.offset)
seg_end = seg_start + ticks_to_ms(result.duration)
try:
data = json.loads(json_str) if json_str else {}
nbest = (data.get("NBest") or [])
if nbest:
best = nbest[0]
best_text = best.get("Display") or best_text
w = best.get("Words") or []
if w:
words_list = [{
"text": (wi.get("Word") or ""),
"start": ticks_to_ms(wi.get("Offset", 0)),
"end": ticks_to_ms(wi.get("Offset", 0)) + ticks_to_ms(wi.get("Duration", 0)),
} for wi in w]
seg_start = words_list[0]["start"]
seg_end = words_list[-1]["end"]
except Exception as ex:
log_message(f"Warning: Could not parse detailed JSON: {ex}")
segments.append({
"text": best_text,
"start": seg_start,
"end": seg_end,
"words": words_list
})
def on_canceled(evt):
reason = getattr(evt, 'reason', None)
details = getattr(evt, 'error_details', '')
if reason == speechsdk.CancellationReason.Error:
log_message(f"Azure STT canceled: {details}")
done.set()
def on_session_stopped(evt):
done.set()
recognizer.recognized.connect(on_recognized)
recognizer.canceled.connect(on_canceled)
recognizer.session_stopped.connect(on_session_stopped)
recognizer.start_continuous_recognition()
done.wait()
recognizer.stop_continuous_recognition()
return {"segments": segments}
def log_message(message):log = getattr(globals().get(‘app’, None), ‘Log’, print)log(message)
def raise_error(message):raise Exception(message)
def _get_azure_credentials():key = SPEECH_KEY or os.getenv(“AZURE_SPEECH_KEY”)region = SPEECH_REGION or os.getenv(“AZURE_SPEECH_REGION”)app_obj = globals().get(‘app’, None)if hasattr(app_obj, ‘Settings’):try:key = key or app_obj.Settings.get(‘azure_speech_key’)region = region or app_obj.Settings.get(‘azure_speech_region’)except Exception:passreturn key, region
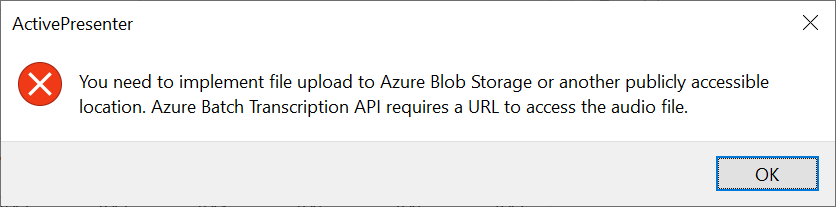
Now comes the problem. The script will be using a python function “azure-cognitiveservices-speech” to let it turn the speech to text in ActivePresenter.
But the script raises the error “Azure Speech SDK for Python missing. Install with: pip install azure-cognitiveservices-speech"“ since even if I have installed this package on my computer, ActivePresenter uses his own python interpreter and not my one installed on my windows.
So my final question is, can I change the folder of the python interpreter that is used by AP somewhere?